I have a program that needs to repeatedly compute the approximate percentile (order statistic) of a dataset in order to remove outliers before further processing. I'm currently doing so by sorting the array of values and picking the appropriate element; this is doable, but it's a noticable blip on the profiles despite being a fairly minor part of the program.
More info:
- The data set contains on the order of up to 100000 floating point numbers, and assumed to be "reasonably" distributed - there are unlikely to be duplicates nor huge spikes in density near particular values; and if for some odd reason the distribution is odd, it's OK for an approximation to be less accurate since the data is probably messed up anyhow and further processing dubious. However, the data isn't necessarily uniformly or normally distributed; it's just very unlikely to be degenerate.
- An approximate solution would be fine, but I do need to understand how the approximation introduces error to ensure it's valid.
- Since the aim is to remove outliers, I'm computing two percentiles over the same data at all times: e.g. one at 95% and one at 5%.
- The app is in C# with bits of heavy lifting in C++; pseudocode or a preexisting library in either would be fine.
- An entirely different way of removing outliers would be fine too, as long as it's reasonable.
- Update: It seems I'm looking for an approximate selection algorithm.
Although this is all done in a loop, the data is (slightly) different every time, so it's not easy to reuse a datastructure as was done for this question.
Implemented Solution
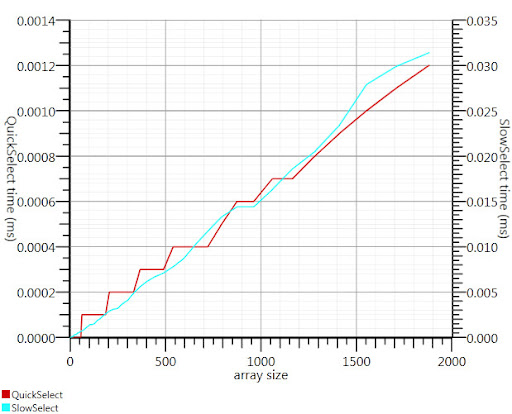
Using the wikipedia selection algorithm as suggested by Gronim reduced this part of the run-time by about a factor 20.
Since I couldn't find a C# implementation, here's what I came up with. It's faster even for small inputs than Array.Sort; and at 1000 elements it's 25 times faster.
public static double QuickSelect(double[] list, int k) {
return QuickSelect(list, k, 0, list.Length);
}
public static double QuickSelect(double[] list, int k, int startI, int endI) {
while (true) {
// Assume startI <= k < endI
int pivotI = (startI + endI) / 2; //arbitrary, but good if sorted
int splitI = partition(list, startI, endI, pivotI);
if (k < splitI)
endI = splitI;
else if (k > splitI)
startI = splitI + 1;
else //if (k == splitI)
return list[k];
}
//when this returns, all elements of list[i] <= list[k] iif i <= k
}
static int partition(double[] list, int startI, int endI, int pivotI) {
double pivotValue = list[pivotI];
list[pivotI] = list[startI];
list[startI] = pivotValue;
int storeI = startI + 1;//no need to store @ pivot item, it's good already.
//Invariant: startI < storeI <= endI
while (storeI < endI && list[storeI] <= pivotValue) ++storeI; //fast if sorted
//now storeI == endI || list[storeI] > pivotValue
//so elem @storeI is either irrelevant or too large.
for (int i = storeI + 1; i < endI; ++i)
if (list[i] <= pivotValue) {
list.swap_elems(i, storeI);
++storeI;
}
int newPivotI = storeI - 1;
list[startI] = list[newPivotI];
list[newPivotI] = pivotValue;
//now [startI, newPivotI] are <= to pivotValue && list[newPivotI] == pivotValue.
return newPivotI;
}
static void swap_elems(this double[] list, int i, int j) {
double tmp = list[i];
list[i] = list[j];
list[j] = tmp;
}
Thanks, Gronim, for pointing me in the right direction!
See Question&Answers more detail:
os 与恶龙缠斗过久,自身亦成为恶龙;凝视深渊过久,深渊将回以凝视…



